I’ve been working on a bizarre little project which involves the very first computer that I ever owned: my trusty old Atari 400. I bought it when I was just 16 years old, and it is probably the artifact of my deep past which is responsible for my career and a heck of a lot of what I’ve enjoyed in the way of geeky hacking.
Without giving too much away, I decided that I wanted to write a simple simulator that would try to emulate the functioning of the sound hardware that is inside the Atari, which all centers around a 4 channel sound synthesizer chip known as POKEY. The details of writing this simulator will probably form the basis of another blog post later, but basically I began with this chapter from the old reference manual De Re Atari.
A quick perusal of the high level description of reveals that the hardware can generate four individual channels of sound, and by setting individual bits, you can change the clock rate at which the sound channels operate to be either 1.79Mhz, 64Khz or 15Khz.
But it doesn’t explain how these numbers are derived.
In fact, the numbers are really only valid for the NTSC version of the Atari 400 and are not specified precisely. This probably doesn’t matter much for most users, but it kind of irked me that I didn’t understand where they came from, and it actually complicated the writing of the simulator.
A bit of digging revealed the following information, which I am going to write down so I don’t have to dig further.
For NTSC systems (the video standard which was common in the United States in those days before HD) these numbers are derived from the NTSC color subcarrier frequency, which is 3.579545 Mhz. A little quick arithemetic will show you that this is 2x the highest 1.79Mhz that POKEY uses to clock sound.
The other two clocks are done by simple pulse division. The nominal 64Khz clock is done by dividing the base frequency by 28, and the nominal 15Khz clock is done by dividing by 114, or at least that’s what appears to be going on. I’m not great at reading the schematics, but this probably reveals some of the details. Assuming the nominal NTSC clock frequency, this makes the “actual” frequencies 63.920Khz and 15.7Khz, respectively.
But anyway, while digging around, I found out that Doug Neubauer, creator of both the POKEY chip and author of the classic Star Raiders game that I spent so much time playing in 1980 has a website where he talks about his days at Atari. Bookmarked here for later consumption. https://dougneubauer.com/starraiders/
I’ve been watching too many YouTube views lately about tool restoration, and as part of my ongoing efforts to equip my home workshop with more tools it means I’ve been hitting more garage sales and picking up a lot more tools which are coated in ferric oxide, and then doing various things to them to return them to working condition. I’ve cleaned up some augers, a couple of crescent wrenches, rusty pliers, screwdrivers, and even a set of four Stanley planes.
Last week, I got a pretty nifty wrench out of a junk pile for just a couple dollars:
I hit the jaw with a wire sheel to try to get the worst of the rust off instead of using the more gentler Evaporust treatment that I have been using before. It was a bit aggressive, and put some scratches into the flat surfaces, but works a lot quicker. The picture above shows the work in progress, with the body of the wrench still untouched, but the jaw worked for just a few minutes on the wire wheel in my 8″ bench grinder. A few minutes with some 120 and 220 grit sand paper will take out most of those scratches, and leaves the wrench looking pretty nice.
I’ll post a picture when its all cleaned up.
But in any case, one of the things I’ve been interested in is “japanning”. That is the dense intensely black and somewhat glossy black coating on internal surfaces of many old planes. Most of the time, the japanning on old planes is still in remarkably good condition, even a century or more after being created. I wondered what this mysterious material was, and could it be duplicated in the modern workshop. For instance, to finish the wrench above, I thought about perhaps applying that to the inset “TRIMO” and “SPUD” logo (maybe with added white enamel lettering).
And, it turns out, it is possible. This video on Hand Tool Rescue details the material and process that you need to go through.
I thought I’d bookmark this, and at some point in the future I might give it a whirl (particularly if I can find a junk sale toaster oven to do the baking part).
I’ve been on a bit of a woodworking binge lately, no doubt fueled by all the creative and talented woodworkers who have made a place on my YouTube subscription list. I’ve also been slowly acquiring used tools of various sorts, working on a variety of shop projects, and even taking a class.
The “class” is actually just a workshop held for five consecutive weekends held at the local high school where you are free to use their tools and avail yourself of the expertise of the instructor. I decided for my project that I’d like to make a laminated workbench top out of cheap dimensional lumber from the local Lowes. I’d never done such a project before, and as is typical for my projects, I dove in with more enthusiasm than pre-planning. But that being said, I also tend to be fairly thoughtful about such projects, and I learn all sorts of lessons in retrospect.
The workshop gave me access to a large jointer and planer, so I settled on a project that I’ve been meaning to do for quite some time: a heavy workbench top, made from laminated boards and designed to be flat. Like, not just sort of flat, but as flat as I could possibly make it. I didn’t “design” anything. I had a dimension in mind (roughly 2’x5′) and just kind of winged it.
I purchased 20 2x4s from Lowes, which were kiln dried Douglas Fir, for roughly $3 each. I spent a small premium (about $.50 each) to get their “premium” version, which did seem to be overall straighter and have fewer knots than their normal version which costs $2.50. Douglas Fir isn’t the obvious choice for a workbench top. It is fairly soft and fairly splintery, but it has a couple of major advantages: it’s available and it is cheap. I can certainly appreciate using a hardwood like maple for this, but my skills are certainly not adequate to justify spending $1000 on what will almost certainly be viewed as a learning attempt.
I cut all the 2x4s to 64″ and then set to work using the jointer. Here’s where I did things wrong.
The purpose of a jointer is to establish two flat, adjacent sides on a piece of work. In the ideal world, you’d then use the thickness planer to copy that flat surface from these “reference” faces to the opposite.
Here is what I think I should have done, and what I would likely do if I was going to make a second one of these:
Stare at each 2×4, examining it for twist and bow.
Joint the wide face, concave side down, until the piece is flat.
Then carefully joint one (hopefully concave face) by holding the reference face against the jointer, to establish an adjacent 90 degree face.
Now we have two flat faces. It is probably reasonable to use a table saw to rip the pieces to width, holding the jointed face down and the jointed edge to the rip fence on the saw.
Then, finally thickness plane all the pieces with the reference face down in the planer.
Sadly, I did some mistakes. None are going to be fatal, but they definitely made some mistakes and are slowing my progress and decreasing the quality of the final result. In no particular order:
I didn’t check the jointer’s fence for square until I was halfway through. Dumb, dumb, dumb. It wasn’t entirely my fault. Even if I had, the jointer in the shop has a fence which takes to periodic slipping, so it’s likely I would have screwed it up. I tried to do another pass to clean it up, which mostly worked (I missed a couple of outliers) but the jointing job was not perfect.
My jointing technique wasn’t perfect. I suspect that when trying to establish the 90 degree reference face, I didn’t do a consistently great job of holding the reference face against the fence, so even when the fence was perfectly setup, I managed to get a couple of boards through which had some taper and twist.
I suspect I planed some boards inadequately, and some convex bowing remained.
Some of the boards sat in my car for a couple of nights, where the variations in heat may have caused them to warp again, even had I done the jointing and planing perfectly.
I was in a hurry. We really only have 12 hours total workshop time, so I decided to forego planing each board separately, and instead went to glue up (with my imperfect stock) in three sections. Each would be small enough to thickness plane again, to establish the final surface.
This is where I was after class last week. I decided to proceed with the glue up as best I could, in three different sections: one of six boards and two of seven. I set them up on my assembly table at home. I took some care to use a set of primitive winding sticks to assure that both bar clamps at the ends were parallel, smeared in a ton of glue, and clamped them up.
A dry run of the first section…
The first section seemed like maybe I used a little less glue than I should have, and despite my best efforts, upon inspection when I was done, I saw that this section had a fair amount of twist (somewhere between 1/16″ and 1/8″) which was faintly annoying. But “once more into the breach”, and on subsequent nights I got the other two sections glued up. They were overalll much better. I did notice that there was still an issue with the first section when I tried to fit the first section to the second.
First section on the left. Note the taper?
Yeah, the edge of my first board has one very poorly cut board which isn’t anywhere close to at right angles with the surface. The first section is pretty terrible.
But I have a plan for salvaging it. Ideally, I could rejoint the section on the wide face and the adjacent edge, but these sections are a little bit wide, certainly not within the capability of my jointer, and not even within the capacity of the workshop jointer, which I’ll only have access to for another week. But where there is a will, there is a way. You can use a thickness planer as a jointer by taking a flat “reference board” and screwing/gluing/taping/attaching somehow the board to that reference sled, and then planing the opposite side. The planer will copy that faux reference face (which is flat) onto the opposite side, and once that side is flat, you can joint the edge and then proceed as usual.
The problem was that was going to take a bunch of time, and I only had a few hours of planer time.
So, I have a new (inexpensive, but highly rated) planer arriving next week.
So, for the class I decided to try to simply stop work on my bench during the class, and we decided instead to put together a simple shop stool that Carmen found on the web using some of my left over scrap Douglas Fir.
It was designed to be made from dimensional lumber with only the simplest tools. We decided to avail ourselves of the jointer and at last clean up the faces. We didn’t do anything (either ripping or thickness planing) to ensure accurate dimensions, but tried to use some care. I made the top out of a glue up that I did as a test before doing my benchtop, which I did thickness plane to a consistent flat thickness.
And, two hours later, we had this:
I am actually pretty pleased. We made a couple of minor mistakes. I misread the instructions for the dimensions for the spreader: instead of 14 1/4″ on the short side, I cut it 14 1/4″ on the long side, which means that the stretcher is actually a bit high. We also followed their direction, which had us screwing the legs directly into the seat first, followed by the addition of the cross bar. This actually seems like the hard way to go. It made it difficult (or impossible) to drive the Kreg screws into the side pieces.
The better technique would be to assemble the two side frames first, perhaps by adding a stretcher at the top as well, and then attaching the top last. I’ve also thought that perhaps I should use a half lap joint to attach the stretcher, and avoid the use of Kreg screws entirely.
Anyway, that’s what’s currently going on woodworking-wise in the shop. More projects are coming, as well as others such as the refurbishment of a used bandsaw I picked up at a garage sale a couple of weeks ago. Stay tuned.
Just some pictures of the wrench after it came out of the bath. I just scrubbed the loose black oxides off with a Scotch Bright pad, and then coated it with some Boeshield T-9 protectant spray to keep it from re-rusting. I don’t think I’m going to do more with this.
After the Metal Rescue soak…
As a reminder, this is what it looked like before cleaning/de-rusting.
Last weekend, I got this rather dirty and rusty wrench at a garage sale in my neighborhood. It’s an odd wrench, stamped with So. Pac. Co., which rather raises the likelihood that it was a wrench used on steam locomotives, and my guess would be that it’s probably closer to a century old than newer than that. I just think it is a cool artifact, even if it probably has a value not much greater than the $5 I paid for it, and I thought it would be get rid of blobs of paint that were on it and clean up the rust, grease and grime that covered (and likely protected) it.
So, I gave it a light scrub with a metal brush to get rid of the loose dirt and scale, and then I sprayed it down with some purple degreasing spray, gave it a few quick wipes, and then put it in a bath of Metal Rescue for derusting, where it has been sitting for a little over forty-eight hours.
After eight hours, it began to show a fair amount of improvement. Some of the rust around the stamped Verona Toolwoorks logo was removed, and I began to see a faint PITTSB imprint below it. Cool. The other bits of engraving on the tool began to stand out further. I gave it a scrub with a green pad. The paint that was on it hadn’t softened at all, so I took it over to my drill press where I had a small wire wheel chucked, and then did a very light pass to just get rid of the paint, doing as little to the underlying metal as possible.
After 24 hours, the main part of the handle was looking not just rust free, but much cleaner. It settled into a fairly constant steel gray. The end of the wrench was still fairly dark and stained. I suspect that a fair amount of grease was still on the wrench, so I gave it another good cleaning. A few small bits of junk were still caught in the sharp part of the jaws, so I fetched a little pick and removed them. And, it’s back in the Metal Rescue. I suspect that when I am home tonight it will be essentially done.
Which brings up the question: “what finish should I apply?”
This is a railroad wrench. It was a hardworking tool, used it a harsh environment. I suppose to some degree the right thing would be to have simply cleaned it and leave it at that, but the rest removal revealed a lot of the details in the casting and engraving that I found interesting. I don’t feel like it would be appropriate to file, sand or polish the wrench. It was never shiny, and to make it shiny would be to turn it into something that it is not.
I could just rub it down with some paste wax or beeswax, and leave it the way it is. That would protect it from rust. But the grayish color of the wrench’s clean steel seems… oddly out of place. I am considering the possibility of bluing the steel, which ironically is the reverse of what the Metal Rescue has been doing. It will basically convert the outer layer of the freshly restored tool to black iron oxide.
What do people think?
I’ve been thinking about what I want to do with the wrench. I’m pondering just mounting it in a shadow box, perhaps with a picture of a period appropriate steam locomotive, or maybe even a model locomotive.
Anyway, if someone has some opinion or ideas, let me know.
Okay, that turned out to be easier than I suspected. I haven’t gotten around to derusting the mystery wrench, but I did do a little bit of simple cleaning, and when I did that, I discovered a couple of markings that were quite helpful.
As in, it gave the entire game away.
The manufacturer is the Verona Tool Works, and was stamped on one side of the wrench under a bunch of grease. A little googling on line revealed that their trademark that I took a rubbing of yesterday.
It consists of a lower V, a T across the top, and then the W running across the middle. A perfect match to what I observed. Sadly, the catalog on the web doesn’t seem to include any of the “alligator style” wrenches like this one. I’m unsure what that means, but a reasonable hypothesis would be that this wrench is of more modern vintage. I’ll try to do more research on this topic.
But a couple of additional markings became visible. I had seen a couple of round letters that I thought might be a double zero, but upon good cleaning, I see them as So. Pac. Co., or the Southern Pacific Corporation, which is indeed a rail line.
Additional markings include a 2×2 array of the letter H (initials? not sure…) and a rather odd set of straight lines and ticks that look purposeful. Both sets of marking appear to be stamped or etched in, rather than cast like the No. 3 and the trademark. I’ll to get decent pictures sometime soon.
I haven’t been able to figure out a date yet. The Southern Pacific Co. remained by that name until merging with the Sante Fe to become the Sante Fe Southern Pacific in 1984, so this obviously predates that. But I think it’s older than that. These kind of wrenches are often listed as useful for steam locomotives, and the Southern Pacific retired its last steam locomotive in 1957. If I were to guess by it not appearing in the 1920s catalog, it might be from the 1930s or so, but more research is clearly needed. I did find a similar wrench on the National History museum website, which similarly dates their version (with a different trademark) from 1900-1955.
If I learn more, I’ll update here.
Addendum: I snapped some quick picks of the various marks.
I took Friday off to make it a four day weekend. Part of the reason was so that I could prep some wood for my woodworking class. I got twenty Douglas Fir 2x4s from Lowes, and cut them to 64″ in length. My idea for my woodworking class was to use their jointer to trim them up, then surface plane them to identical thickness and laminate them together to make a 2’x5′ workbench top. I got them all cut on my chop saw on Friday, and got them loaded into my car. I was hoping to get them all jointed and planed, but my general inexperience and a failure to double check the fence angle on the jointer meant that I only got the jointing complete in three hours. Still, it was a pretty good morning.
I took Carmen out to lunch, and then headed home. As I was driving along San Pablo, Carmen spotted a yard sale, and suggested we turn around and give it a peek. “I see tools!” Okay, I thought I’d give it a quick peek, even though I had no cash with me, and my SUV was already laden with the wood that I had cut for the class. I could always go back and get cash, I suppose.
I ended up going to an ATM and getting cash.
First of all, I picked up this Jet JWBS-14.
It got it for what I consider near “steal” pricing. It isn’t without its flaws. A brief inspection revealed that the table was oddly askew not just left to right, but front to back (the left rear corner was high) and the table was fairly loose and tightening the trunnion bolts along the bottom didn’t result in a lot of improvement. I ducked under, and detached the table, and flipped it over. I know jack-diddly about bandsaws, but even I could tell something was odd. The seller had mentioned that he had “repaired” the table, but I wasn’t all that concerned given the price. But the repair didn’t strike a lot of confidence in me. Apparently the two trunnions that sit under the table and allow the table to tilt left to right were replaced by these black pipe monstrosities:
Astute viewers will note that the left one has a single elongated hole, where the second one has two holes. My guess is the one on the right was made first, but the measurements were way off. But apparently he didn’t learn a lot making the first, because the second has the whole that is super wide, seemingly because it wasn’t drilled square in the first place. The welds and cuts are… well, they just aren’t very good. And nothing is deburred, it really just looks like a mess. I suspect that they aren’t very well centered or aligned, which probably introduces the front to back tip that would be difficult to sort out. It probably didn’t help that only four of the six holes were populated by screws, likely because the remaining two holes were not aligned with where they needed to be. It didn’t give me confidence that among the four screws there were three different types either. Luckily, these didn’t actually damage anything. I ended up ordering a pair of proper castings to replace these, and they should arrive in a couple of weeks for a modest cost of $40.
There are three other minor issues that I’ve found so far:
There is a front knob/latching bolt for the top front door which is simply missing.
The alignment pin on the table is missing.
The stop bolt that sets the table at 90 degrees is simply missing.
But the belts and motor appear to be in good shape. It runs very quietly. The bed had some fairly ugly scratches and a modest amount of rust, but a little scrubbing with WD-40 and a green pad got rid of 75% of it in just a few minutes. When I am ready to install the trunnions, I’ll finish that up. The fence is pretty janky as well, but I could probably make some improvements on that. In all, I’m very pleased.
But the guy had some additional hardware that was also sufficiently antique to be interesting. I couldn’t resist, given my desire to restore rusty things lately. I found these four items fairly quickly:
Proceeding from left to right, I found a (probably not particularly old) No. 80 Stanley card scraper. It did not include the blade, but was otherwise in pretty excellent shape. It just needs a little cleaning and a replacement blade, and it should be able to return to service.
Next was a little Stanley No. 120 block plane. I doubt this one is very old, but I would guess it is not super modern anyway. I got a similar blockplane for $2 a couple of months ago, but this one has a more sophisticated blade tensioning adjustment, and is a heavier casting, which makes me believe it is of modest age. I’ll try to get it tuned up and ready to go sometime in the next few weeks.
Next was a nice little marking gauge. It has two pins on one side, and one on the other, and so can be used to either mark mortises or just cut simple marks from you reference edge. It’s made from a dark wood (rosewood?) and brass, and isn’t in flawless condition, but again, I paid only a small amount for it. I hope to get it sorted out and back in service after cleaning it, and polishing the brass a bit.
And of course the last was a genuine antique: a very rusty “breast drill brace.” As you can see, it dirty and has a fair amount of service rust, but the mechanism works. It’s pretty cool. The chuck is set for the square type of auger bits (like the antiques I restored previously) so it will be pretty neat to restore.
I was all set to leave, and I found one more item: an old “alligator wrench.”
These kinds of wrenches were apparently used in the railroad by steam fitters and the like who used them to yank on pipes. This is a No. 3, about 15″ long, and just seems like a cool old wrench to add to the collection. I think this will be the test subject for my new and improved 5 gallon electrolysis setup. There are a few markings on it which are hard to read, but which are pretty faint. I tried to get a rubbing of a symbol near the head, and found this:
Symbol of the Illuminati? Blue print for a flux capacitor? I have no idea. There are some other faint letters and numbers on the wrench in addition to the embossed No. 3, perhaps after cleaning it will be more apparent.
Carmen also helped me do some garage tidying and vacuuming. I installed a retractable 40ft extension cord which should help keep me from tripping over extension cords. It looks a lot nicer in the shop.
Totally psyched by the addition of the bandsaw. Hope you all had a good weekend too.
So, part of my incentive on working on my WSPR beacon was one of my coworkers decided to try to do some operating from the local Emeryville Marina, and I thought it might be nice to use the opportunity to try to pack up my WSPR setup and see if I could get some spots using solar/battery power.
I wrote up some of the early experimentation to get the beacon working, but as of then I hadn’t actually gotten on the air. To do that, I needed two things: an antenna and (to be a good RF citizen) a low pass filter to make sure that I wasn’t scattering horrible harmonics everywhere. While it was true that I was outputting a scant 10mw, I thought that being a good citizen was important.
I had some yellow T37-6 cores lying around from a previous bout of homebrew exploration, and dug out an article on constructing harmonic filters by the awesome (but sadly SK) George Dobs, G3RJV. I dug out some copper clad and wired up the filter using some islands that I punched out of scrap copper clad board. I am a total novice at this, so the board layout is terrible and stupid, and the leads are too long: in short, everything I did should be viewed with skepticism.
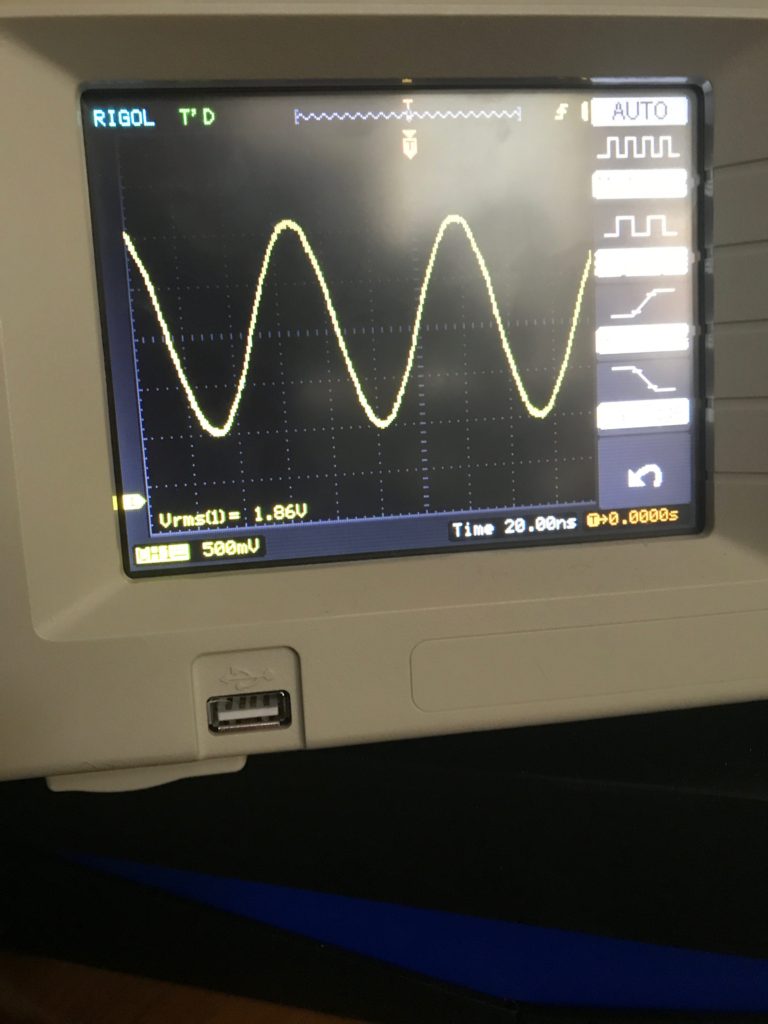
But as crappy as it is, it seemed to work. I snapped a quick picture of the output as it goes to my antenna, and the previously ugly triangle-ish wave now resembles a reasonable sine wave.
I must admit that I was somewhat befuddled by the Vrms as measured by my scope. The equation for output power suggests that power equals Vrms squared divided by the resistance. If we assume my antenna was a nominal 50 ohms (it’s not, but let’s pretend) then this would indicate an output power of nearly 70mw, which doesn’t really make sense. My antenna had only been “tuned” in the grossest sense, and probably had an SWR of around 2.5:1, which suggests that it’s characteristic impedance was probably a lot higher. For the purposes of WSPR, I configured my output power as 20mw, which I thought was probably still generous, but in the right ballpark. I made a note to myself to figure this out later.
I still needed an antenna. While cleaning my garage, I found a pair of 20m whip antennas and an MFJ 347 mini dipole mount. I mounted these on a small piece of conduit, and then built a quick stand to hold it up, consisting of a 5 gallon bucket, a small round of particle board that I had left over from another project, and four pieces of two by fours to act as feet. Here it is, setup on my back patio. Yes, I know that the antenna is mounted too low to be good or efficient. This entire project was designed to be a hack, and for maximum ease, not permanence.
I set it up and home and set it beaconing. I didn’t get the torrent of spots that I had gotten when I had used a similar setup with 5w of power (using my FT-817) but a few minutes later I did get a spot from KA7OEI from DN31, a distance of about 933 km.
Huzzah! Thought I. I was ready for field day. Mind you, the entire thing was still just a pile of breadboards constructed out of wire. I decided to use my Chinese charge controller and a 20w panel to drive it and to recharge a 7aH lead acid battery. I packed it all up and headed to Emeryville on Field Day.
I’d like to report success, but the fact is that once I got it set up, it was apparent to me (by a lack of blinking lights and LEDs) that it wasn’t working. I wasn’t sure what was wrong, but I had failed to bring my laptop so debugging it in the field seemed like it wasn’t going to happen. After a couple of hours, I decided to pack it in. Sad.
Setup, but disappointingly didn’t generate any RF or even a single spot.
The next day I unloaded it from the car and tested it out. The Arduino and the LCD unit seemed completely dead. I reflashed the code onto a new Arduino Nano, moved it all to a single breadboard, and reset it up in the backyard, and it has been beaconing on 20m, entirely powered by solar since then.
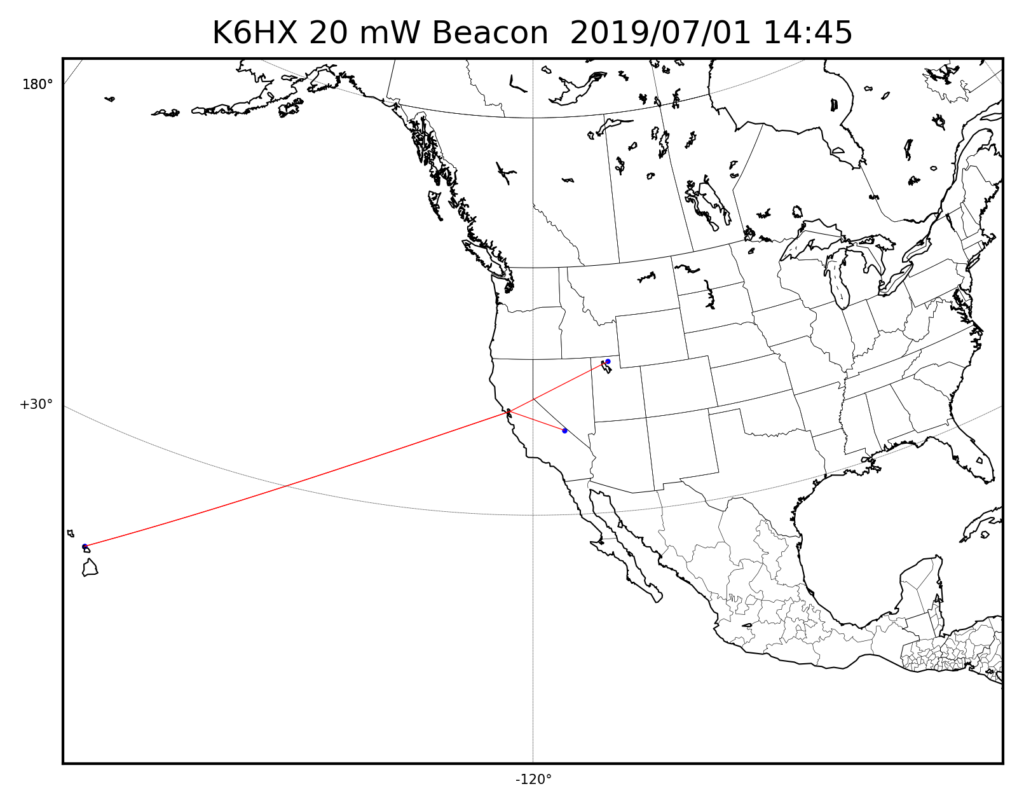
Since then, it has been spotted by 15 unique stations. By far and away the most reliable connection has been to KA7OEI-1, who has heard it 337 times in the last week. ND7M comes in next, with 118 spots. Distance records are pretty much evenly split between AI6VN/KH6 in Hawaii, and WD4ELG in North Carolina.
I made a small map which updates frequently, showing all the spots for the previous 24 hours. You can view that from my home webserver, at least until I get bored with it and take it down. I used the Python matplotlib to generate the maps, this one being an example.
I’ll probably try to get this up more or less permanently, and may add a small RF amplifier to boost its output to around 100mw. I will probably also shift to using an ESP8266 based module so that I can monitor and control the system via WiFi. I’ll update you when I get that going.
As part of my attempt to get into woodworking and develop some actual skills, I have been keeping an eye out for what would best be described as “junky piles of rust” at garage and estate sales. I have been updating my twitter feed with pictures and short comments, but I thought it might be fun to include some of what’s been going on here, in a longer format, and in a way that is more permanent and findable once my twitter posts fade into the past.
First of all, about a month ago I found someone selling this old Delta jointer for a good price. It was dusty and dirty, but entirely functional. I’d been looking for a jointer for quite sometime, as I think a jointer and a planer will make all sorts of woodworking more productive and more enjoyable. This one may not look like much, but the bed and fence are actually just dirty and not very rusty, and the planer works, although I think the blades could use a bit of sharpening. The stand is fairly rusty though. I got one quote for having it sand blasted and powder coated, but might still just attack it with my angle grinder and a wire brush. I’m also not fond of the power switch situation. It is basically a wire loop on the rod you see in the back of this picture that flips a power switch. I think I’ll find a way to mount a safety switch with the big paddle “OFF” on the front of the stand so it is easier to turn off and on. It’s also quite heavy, so I might think about figuring out a way to move it around easier.
Last friday, I found a guy selling some Stanley planes, and went to take a trip. I wanted a No. 4 and a No. 5, but ended up coming away with two No. 4s, a No. 5, and a No. 6. They were in what I would call “fair” shape: with a fair amount of surface rust and staining, but with all the parts and no obvious breaks, pitting or damage.
I’ve only started to work on the first of them, the No. 4 on the top which from the looks appeared to be the older of the two No. 4s. A little reading on the web made me believe that it is a Stanley Type 19, made between 1948 and 1961. I disassembled the plane and had a look at the various parts. The sole was perhaps the most interesting part:
As you can see, the bottom was fairly rusty and stained. I thought about using my electrolysis setup to get rid of it, but it was already busy with another project (see below) so I got out some of my trusty Metal Rescue and set it soaking. Four hours later, I pulled it and and gave it a light scrub with a Scotch Bright Pad. The results were really impressive:
There is still a little light staining, but the surface is overall very smooth. The blade and chip breaker had a small amount of rust which was also completely gone after the soak. I still have to clean and polish the nuts and bolts. I did try some Brasso on one of them, which looks like it worked just fine:
I should have the parts all reassembled and ready for sharpening soon. Then it will be onto one of the others. The bottom of the No. 5 is particularly bad, and may have some actual pitting. I’m excited to see how it will turn out.
I passed another garage sale and picked up a rusty Crescent wrench (like, actually made by Crescent) for $.50, along with a rusty chisel. I figured I could practice my sharpening skills on the cheap chisel.
There was only mild rust and some pitting on the wrench, but as a bonus it was frozen and wouldn’t move. I thought I’d give a shot at trying to use electrolysis to both get rid of the rust and see if it would free the mechanism. About fifteen minutes into the treatment, I saw small blobs of grease floating to the top of the bath, and four hours later, the top of the bath was the orange rusty scum that I’ve come to expect. I pulled the wrench out, and all the orange rust was gone, but there was still some scaling, and the black oxide was pretty hard to scrub off. And it was still frozen. So I let it go for another four hours, without much change. I ended up putting a couple drops of 3 in 1 penetrating oil on it, letting it sit for ten minutes, then giving the thumbwheel a couple of gentle taps with punch and a hammer. It yielded fairly quickly, and running it back and forth a couple of times it began to work pretty well. A screw holds the thumbwheel in place. I found a good fitting screwdriver and tried to get it to back out so I could remove the jaw, but it wasn’t cooperating. I left a couple more drops of penetrating oil on it, and an hour later, it came out easily. The jaw, screw, and thumbwheel separated from the main body, as well as a small brass wire ring (a washer?) that I wasn’t expected. I took a wire brush and some degreaser and cleaned these parts, and then let them soak for a bit in some Metal Rescue. I’ll get these back assembled shortly.
Restoring broken tools to working condition makes me feel virtuous. It’s also pretty fun.
Anyway, that’s all the “rust” related activities for the week. Once I get the No. 4 reassembled, I’ll show some more pictures here.
I’ve been mostly working in my workshop on various projects related to woodworking, but last week one of my coworkers reminded me that Field Day, the yearly day where radio amateurs take their equipment into parks away from the comfort and ready electrical supply and operate under conditions which are meant to simulate (at least someone) operating under emergency conditions. In the past, I haven’t much paid attention to it, except perhaps to go see what people are up to in several local parks.
This year I thought it might be fun to resurrect some of my past ideas/skills and at least do some minor bits of operating. But I also thought it would be fun to use some of my homebrewing skills to bodge something together as a kind of tech demo and excuse to tinker in the shop.
A decade ago, I went through a phase where I was interested in beacon operations, operating a small, low-powered, automated transmitter that could be heard around the world. This was no doubt inspired by Bill Meara’s chatting about it on his Soldersmoke podcast, and took the form of both QRSS (low speed CW) and WSPR (Weak Signal Propagation Reporter) transmissions. I first started doing WSPR back in 2008 by generating the necessary tones and playing them back through iTunes into my FT-817.
At various times I started homebrewing small transmitters together, but I never really got anything off the bench and into operation.
But I’m hoping to do better between now and Field Day.
Over the years, I’ve accumulated a lot of parts that should make this possible, or even easy. So currently on my desktop I’ve got the following parts:
An Arduino Uno. I could use any of a number of other microcontrollers, but the Uno is certainly capable. I may replace it with an Arduino Nano in the final version.
An Adafruit SI5351A breakout board. In the past I’ve tinkered around with simple low powered crystal oscillators, but this board is insanely cheap ($8) and can generate three different oscillator signals simulataneously. The board has a great driver written by NT7S that makes it dead easy to control.
A cheap GPS module. Ideally, our beacon needs to know where it is and what time it is, and the GPS module can provide both. I’ve had a couple of these in my parts bin, sitting unused, but I soldered some female headers onto the wiring harness and smeared a bunch of hot glue on it to make a crude header, and it worked perfectly.
A 4×20 LCD display. I had all sorts of different display technologies available, but this one is larger than most and easy to display.
And… that’s about all you need (other than software) to make a WSPR beacon. So that’s what I did. The program boots, syncs with the GPS and waits for it to get the time and position, and then puts the Maidenhead grid and time on the display:
Bad cell phone picture, but it shows it working…
The program then waits for even numbered minutes to start, and sends the appropriate code sequence. Across my living room, I had my FT-817 setup (without an antenna) and it could easily hear the oscillator running, and it decoded the appropriate message.
Reception from across my living room!
There is still quite a bit of work left to do before Field Day.
I need to construct a harmonic filter for the output. I took a quick look at the output, and it was a pretty triangular waveform, definitely not appropriate for sending out over a real antenna, even at the 20mw or so output level it will have.
I need to bodge together an antenna. I have a pair of 20m whip antennas. I could use either one as a vertical, or I could use an MFJ-347 that I have in my parts box to construct a mini-whip dipole. Not sure what will be best. That will probably be this weekend’s work.
I should get a case to protect it and transport it. Right now it’s a pile breadboard with a bunch of wires hanging off it. I’ll probably just make a little wooden half box to mount the LCD, switches, and connectors, and then just double stick tape everything else.
The software still needs some work.
That’s all I have time to write up this morning. Stay tuned for more updates and probably video from Field Day where I show this in operation.
Yesterday I wrote up my (successful and positive) results at using the commercial product Evaporust to remove rust from some of my smaller rusty auger bits that I got in a garage sale. Last night I got home late after a trivia competition, but decided to toss together a test for using electrolysis using bits and pieces that I had gathered in anticipation over the last week.
First, warnings. While I consider most of this stuff to be pretty safe, I am not an expert on electrolysis or the risks of doing so. You are encouraged to do your own research on the subject. Electrolysis will release small amounts of hydrogen gas which could be a fire hazard, and it does involve chemistry. Do your own research and stay safe!
First of all, the basics: you need a plastic (or non-conductive) container. I decided to use a clear plastic Steralite container that holds about 1 gallon. It’s small, but I wanted to start small, and it was large enough to hold a couple of small items without trouble.
Next, I needed an electrolyte. Water by itself is a poor conductor of electricity, and you need to change that. The electrolyte that seems universally used is sodium carbonate, or washing soda. This is different than sodium bicarbonate, which we know better as baking soda. I know I’ve seen washing soda at various places, but I’ll be damned if I could find a local place that carries it. As it turns out, according to the web you can convert baking soda into washing soda by heating it. I spread a fresh box of dollar store baking soda onto a glass dish and baked it at 400 degrees F for an hour. The overall texture didn’t change all that much, but it did appear less powdery. I’ve heard it described as “more like sand” which didn’t really match what I saw, but I decided to press forward anyway.
You’ll also need a piece of scrap iron to use as a sacrificial electrode. It’s going to acquire a bunch of rust and gunk in the process, so it doesn’t need to be pretty or nice. I was going to use a scrap of steel strap from my workshop, but then found that lots of people use rebar. For convenience, I stopped by Home Depot and picked up two 1ft lengths for about $1.25 each. One thing you should not use is stainless steel: the chrome in it is not something you want to screw with, it can form all kinds of toxic nastiness. I’ve seen people do this online, but DO NOT DO IT.
I needed some wire to hook it up. I had a scrap of Romex lying around, which has an uninsulated ground wire inside. I stripped it, and pulled two pieces about 18″ long. I wrapped some of the wire around the rebar, making a short loop that I could pass a piece of wood to suspend it in the solution. I did the same thing for my No. 16 auger bit.
Oh, and you need a power supply. Lots of people use manual car battery chargers. I had picked one up from a garage sale a few months ago, but I decided that I could use this as an excuse to pick up a little bench top power supply that would allow me to supply it with carefully regulated power. There is probably no need for this, but it gave me an actual number I could stare at. I ended up buying this one from Amazon for around $50 by Eventek. Using a current limited supply gave me some small measure of safety: if I set the current limit low, if the piece and the scrap electrode did accidently come into contact, the current would be limited and I wouldn’t get a short circuit. (But still, don’t allow the two to come into contact.)
Once I got all this stuff together, it was pretty easy to setup. I wound the wire around the drill bit and rebar, forming a loop so that they would hang suspended in the middle of the container. I filled it with about 1 gallon of water, added 1 tablespoon of my homemade washing soda, hooked up the power supply (important: negative to the piece you are trying to de-rust, positive to the scrap, not the other way around) and set the current limit to be about 1 amp, and turned it on. It stabilized at around 12v, which is precisely what I wanted.
Power supply has the red led on, indicated constant current limited at 0.97 amps.
Immediately I could see bubbles forming around the length of the drill bit. Some cruft began to loosen, seemingly mostly from the rebar (at the bottom below, the drill bit is on the top.)
It’s bubbling, and gunk is coming off. It looks like… SCIENCE!
I snapped a quick video with my cell phone camera to help show the bubbling:
Seemed to be working, so I went back into the house and watched some TV. I came back out a couple of hours later, and was met with this rather disgusting looking sight.
It looks worse than it is. I’m told that if you use graphite rods as your scrap electrodes, you won’t get this sludge, but it is mostly just rust. I decided at this point to reduce the current to just 0.5 amps and let it go overnight. This was from an overabundance of caution more than anything else. At just 0.5 amps, the voltage dropped to about 7v and the bubbling was less vigorous, and I left it until this morning.
Because of the reduced vigor in bubbling, a lot of this sludge had settled out and things appeared pretty calm. The auger bit seemed pretty black, so I thought I’d call this initial run done and fish it out. I unwrapped the wire, and then gave the drill bit a quick rinse. Much like my experiment with Evaporust, the bit seemed to be covered in a bit of black residue, but didn’t have any rust. I tried a bit of scrubbing with a green kitchen pad, and then briefly upgraded to a stiff wire brush to try to remove the remainder. I didn’t work on getting it perfect, just wanted to make sure it was clean. Here is a comparison shot of it compared to one of its rusty mates (the No. 14 from the same box).
I suspect that with a bit more hand work (and a smaller wire brush) I could get most of the black off. The difference in texture between the two is quite startling: the treated bit is very smooth and doesn’t feel rough or porous.
Overall, I consider this a success! So much so, I took the other drill bit and set it going in the goop for the day. Eventually I’ll get all the bits processed.
Given that these bits began their stay in my garage looking like this:
I am pretty happy with the overall results. Either Evaporust or electrolysis seems like an effective way to restore rusted old tools, I can recommend either. The nice thing about Evaporust is that it’s simple and straightforward: you just soak the part until its derusted. The nice thing about electrolysis is that it is probably less expensive to scale to large scale. I’m thinking of using it to restore some old handsaws that I have. Stay tuned.
It is Monday morning, and I’m enjoying my coffee before heading off to work. All in all it was a pretty productive three day weekend, and I thought I write up a quick note about what I got accomplished.
First of all, I got some woodworking in the shop done. I finished constructing the mover dollies that I’m going to put under the shelves in my garage, and got one installed. They work great! When they are all done, I will be able to move, rearrange and more easily access and sort the contents of my shelves, which should help keep that part of the garage both compact and accessible.
I don’t have any pictures of the completed frames, but here they are assembled, just minus finish and the casters. The bottom of each of the plastic shelving units has some protruding plastic pipe that normally a plastic molded foot attaches to. Now, they just drop into the holes in the dolly. I didn’t see any reason to permanently attach them: the fit is tight enough that simple friction and gravity should do the work. Carmen and I put some Thompson Water Seal on them so we could hose them off if they get dusty or dirty. I must admit I could have done a better job of that, but the wood is pretty marginal and we didn’t do a lot of work trying to sand them or get them ready for finish. Meh. It’s shop furniture.
A lawn tool cart, nearly finished.
I also built another cart this weekend. This one was designed to hold all or most of of our lawn tools: rakes, shovels, and the like. We had a pair of the pictured green organizers, which were designed to be bolted to the wall. By themselves, they are too flimsy and have a poor center of balance, so you can’t really make them work as a stand alone holder. So, I designed and built this cart using a couple of 2x4s and basically a full sheet of some scrap CDX 3/4″ plywood that’s been sitting in my garage for the better part of two decades. The picture above shows the basic design. It needs some sanding, paint (Carmen is threatening to make it a bright color) and the casters mounted on the bottom. My original design was going to use the green racks on both sides of the center, but now I’m beginning to think that certain heavier tools like a grub how could be better handled by building a simple bin on one side. I think I’m going to hold off on installing the organizer on one side, and see how the cart overall works out. If I decide to build a bin on the back side, it will probably be about 60% of the height of the separator wall, and will likely just be a front frame with a couple of stretchers.
I’ll have to start designing projects before I start cutting.
Anyway, the last thing was I worked on was the rusty auger bits that I purchased at an estate sale last week.
Ick.
By way of example, here is a reminder of what they look like. These are the largest examples, and show the rust most clearly. There are a couple of things going on here: simple dirt, rust, and I think that they were probably also rubbed down with something like linseed oil which polymerized into a varnish like coating in spots. Yuck. I thought I’d run a couple of experiments to see if I could get them cleaned up.
I took a wire brush to a couple of the smaller specimens. It was pretty good at getting rid of the oily varnish layer and removed a lot of the surface scaly dirt and rust, but the overall look was still pretty rusty.
I’ve been watching YouTube videos, and a lot of them recommend a product called Evaporust for getting rid of surface rust. You basically just soak the piece in Evaporust, them scrub a bit with a pad afterwards, and.. voila. I went and bought a quart ($10) from a nearby auto parts store, found an old quart water bottle with a cap I could sacrifice to the gods of chemistry, and set it to work.
After eight hours of soaking, all the red iron rust is gone, converted to this thin layer of black oxide…
After eight hours of soaking I fished them out. Very nearly all traces of red rust is gone. The parts had a thin layer of black schmutz on them, which mostly came off with a little scrub from some green pads. I snapped the picture above after only the most cursory wipe down. A little additional polishing made them look very nice, if not entirely brand new.
Evaporust gets my thumbs up, except that it’s a little expensive. I will be testing another potentially cheaper method for removing rust, particularly for big parts: electrolysis.
Basically the idea is to submerge the part in a conductive solution, attaching the part to the negative side, and a sacrificial piece of iron or graphite to the positive side, and then apply a current. The advantage of this over Evaporust is that you can scale it up and submerge very large parts for much more modest costs.
I’ve very nearly got that setup, and will likely use some of the larger auger bits (perhaps the No. 16 bit, which is actually fairly bent) as my initial test. I’ll write up my results when I get them done.
This week, I picked up an ancient, decrepit box of rusty auger bits at an estate sale. The label inside refers to 1884 and 1887 patents by the Irwin Auger Company of Wilmington, Ohio, and it appears to be a fairly complete set, albeit in a wooden box which is pretty close to losing all mechanical coherence.
Why, you may ask, am I buying such a crazy thing? I ask myself the very same question. I guess part of it is that I just find old tools to be, well, very interesting as artifacts of what we would today call “Maker Culture”, but which would have simply referred to as “knowing how to do stuff” a century ago. For the modest investment of $10, I get to embark upon a journey not motivated by anything as mundane as “practicality” or “efficiency”, but I get to glimpse a world where wood didn’t come in the shape that you wanted to, and if you wanted to impose your ideas upon it to construct it, you do using tools which today seem quaint, but which used to be fairly common.
What am I going to do with them? Well, that’s a fine question. In the short term, I’ll probably test a couple of different ways to restore them by removing rust, sharpen them, and maybe even work on cleaning and restoring the box that they came in.
Ferrous oxide!
They are, after all, a pretty rusty mess. But other than that, the condition appears fairly good. I’ve been meaning to test two different techniques for rust removal that I’ve seen demonstrated in the my binge watching of restoration videos on YouTube: either using a chemical like Evaporust (actually, using Evaporust) or removing rust with electrolysis.
If I accomplish anything interesting using either, I’ll write it up here, of course.
I really owe all this insanity to Rex Krueger and his YouTube channel. This episode is what lead me to pay $1 for a brace at a garage sale a couple weeks ago, and to pick up this box this week.
When cleaning the garage a while back, we discovered our old pink “Fight Breast Cancer” edition Roomba. For some reason, we had put it away and hadn’t been using it for years. The battery pack was dead, but a quick order on Amazon had returned it to working order. It happily scurries around the living room, generally making the carpet look a little nicer, and providing some entertainment (or is it anxiety?) for the cats.
But using it in our dining room was a bit problematic. The dining room is about 4″ higher than the living room, separated only by a small step. This old Roomba seems to not have a sufficient sensor package to detect this, and will gleefully head over the cliff, usually getting high-centered as a result and unable to continue. To combat this, Carmen had an elaborate if bulky system of empty cardboard boxes that she could deploy.
But they were big, and bulky. And ugly.
I came home the other day and noted that she had purloined a strip of 1/4″ plywood from my shop. It was roughly 48″ x 10″. She placed it up against the drop off, merely holding it in place with one of the many shoes that we have in our rack in the nearby hall made the Roomba turn away.
She asked if I could make some more.
Well, as it happens, yes I can. Because my shop is (reasonably) ordered now. I was pretty sure I could make some additional strips to match this original one, and span the 10 feet or so of space of this drop off.
I headed toward the garage. Do I have some more 1/4″ ply? But as I am walking through the hall to the garage, I stare over at the side where a picture frame and some leftover Pergo strips have been sitting for years.
And a piece of 1/4″ hardboard.
Nice! I go into the shop with the 1/4″ board, don’t even bother measuring. Just set the rip fence on my little table saw to duplicate the whip, and quickly take off two 48″ strips.
Carmen was watching me, and as I take off my safety glasses begins to talk about how we might store them. I glanced over at my drill press, where a 1 1/2″ hole saw is still chucked after my experiment with creating dollies for the bottom of storage shelf.
Three minutes later, each of the segments has a nice, finger friendly hole in the corner so we can hang these pieces on a hook in the closet when they are not needed.
This is a dumb project. Perhaps even pointless. But I am taking pleasure in the notion that something which is this simple and dumb could be accomplished so simply and with so little planning.
It’s why I am interested in getting my shop organized in the first place.
Okay, it’s not really a “shop”. It’s really just my garage. But then again, it’s hardly ever had a car in it in the last two decades, so calling it a garage is perhaps even a bit more of a stretch. But I’m trying to convert it into a place where I don’t mind spending time and have the tools and space necessary to accomplish some kinds of “making” that I haven’t done before and which can’t really be done inside the house proper.
Carmen and I began the day out back with a simple chore: laying down landscaping cloth and mulch in the small flower bed just in front of our retaining wall. For those of you who weren’t talking to me during the incredibly annoying construction process that was the retaining wall, I had the old rotting redwood retaining wall replaced with a properly engineered concrete retaining wall, with new drainage. While we were at it, we started on “zero-scaping” the backyeard, which in the area of our patio mostly meant replacing it with gravel and even more changes to the drainage. That process ultimately was good, but it was mentally exhausting, and we haven’t really done much with the space since last year. As the result, we got a fair amount of weeds and the like growing up through the gravel. Over the last couple of weeks, we’ve tidied that up and sprayed, and got the grass that grows up on our hills trimmed back to comply with fire regulations.
But it’s about time that we got some low improvements going. Over the last week or so, we’ve pressure washed the (rather ugly) concrete patio so it is at least cleaner, and we thought that we should fill the bed which sits in front of the flower bed with some groundscaping cloth and mulch.
When we began this morning, we had this:
And with an hour or so of work, we transitioned into this.
I tilled the area a small bit (mostly in the corner) and raked the debris out and generally cleaned up the ground, and then laid down a roll of cloth and piled out six bags of new mulch. It still needs a lot of work, but it was what I had planned for the day, so I can’t really be unhappy with it.
Then, off to the shop! Carmen had done a fair amount of cleaning herself yesterday, so we had some more square footage to move around in. We are getting to the point where organizing the four 36″ x 24″ plastic shelving units on one side of the shop has risen in my priorities. They are big, and seem to collect an annoying level of junk, none of which is easy to organize or clean because out of necessity, they are too close to one another. But a few weeks ago, I saw this workspace hack done by Fran Blanche:
She basically took a simple mover’s dolly which you can get pretty inexpensively from Harbor Freight, and adapted it to mount underneath the shelving unit that she had. I thought this was a cool idea. But the shelving units that I’m using are a bit bigger than hers. The larger dolly from Harbor Freight is 30″x18″, and my shelves are 36″x24″, which means I’d have to split it along both dimensions. That doesn’t seem right. In pondering it, I have a new solution. It involves just 2 pieces of 2×4 and four inexpensive casters, and I’ll be writing that up when I test out the idea.
But I did have one smaller metal shelving unit which we 12″x30″, and I thought it would be possible to adapt it with just a couple of 2×4 additions. So, I gave it a whirl, and it worked great.
This shelving unit used to sit next to my drill press and gathered all sorts of junk. But now I can easily move it around, or spin it either to sit flush against the wall, or perpendicular to it. I can even roll it across the garage, load stuff onto it or off of it, and then roll it back. Nice! I think that when my other shelving units are on wheels, I’ll really enjoy them as well.
That’s my weekend so far. I might spend some time working on Carmen’s potting bench tonight, which will be great to put behind me so I can then work on a better stand for the drill press.