A couple days ago, one of my Twitter or Facebook friends (sadly, I forgot who, comment if it was you, and I’ll give you credit) pointed out this awesome page:
Reversing Sinclair’s amazing 1974 calculator hack – half the ROM of the HP-35
It documented an interesting calculator made by Sinclair in the 1970s. It is an awesome hack that was used to create a full scientific calculator with logarithms and trigonometric functions out of an inexpensive chip from TI which could (only barely) do add, subtract, multiply and divide. The page’s author, Ken Shirriff, wrote a nifty little simulator for the calculator that runs in the browser. Very cute. It got me thinking about the bizarre little chip that was at the center of this device.
I’m kind of back in an emulator kick. I recently had dusted off my code that I had started for emulating the 8080 processor. I had originally wanted to implement a version of CP/M, but I remembered that the 1978 game Space Invaders was also based upon the 8080. It wasn’t hard to find a ROM file for it, and with a little bit of hacking, research and debugging, I had my own version of Space Invaders written in C and using SDL2, running on my Mac laptop.
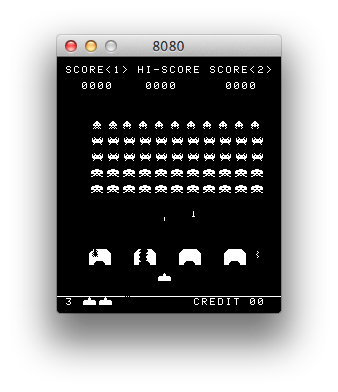
Fun stuff. The sound is a little crude: most of the sound in the original game was generated by a series of discrete circuits which you can find on this page archived via the Wayback Machine. I briefly played around with simulating some of the sounds using LTSpice based upon these circuits (it appears to work fairly well), but I haven’t got that fully integrated into my simulator yet. For now, it just queues up some recorded sounds and plays them at the appropriate time. Everything is currently working except for the classic “thump… thump…” of their marching. I’ll get that working sometime soon.
Anyway, back to calculators. One thing on Ken’s page kind of made me think: he mentioned that the HP-35 had taken two years, twenty engineers, and a million dollars to develop. Mind you, the HP-35 was pretty revolutionary for its time. But I thought to myself “isn’t a calculator an easy hobby project now?”
After all, I had assembled a KIM-Uno, Oscar’s awesome little $10 board that emulates the KIM-1 microcomputer:
In fact, the KIM-Uno implements a floating point calculator as well. It’s brains are just an ordinary Arduino Pro Mini wired on the back. Arduino Pro Minis can be had for less than $3 from China. Could I make a fun little calculator using that as the basis?
My mind is obviously skipping around a lot at this point.
Of course, a bit more googling revealed that someone had done something very similar using the MSP430 chips from (appropriately enough, also manufactured by Texas Instruments). Check out the build thread here.. It’s pretty nifty, and uses a coin cell to drive it, as well as some very classic looking “bubble LED displays”, which you can get from Sparkfun. Pretty cool.
Anyway…
For fun, I thought it might be fun to write some routines to do binary coded decimal arithmetic. My last real experience with it was on the 6502 decades ago, and I had never done anything very sophisticated with it. I understood the basic ideas, but I needed some refresher, and was wondering what kind of bit twiddling hacks could be used to implement the basic operations. Luckily, I stumbled onto Douglas Jones’ page on implementing BCD arithmetic, which is just what the doctor ordered. He pointed out some cool tricks and wrinkles associated with various bits of padding and the like. I thought I’d code up a simple set of routines that stored 8 BCD digits in a standard 32 bit integer. His page didn’t include multiplication or division. Multiplication was simple enough to do (at least in this slightly crazy “repeated addition” way) but I’ll have to work a bit harder to make division work. I’m not sure I really know the proper way to handle overflow and the sign bits (my multiplication currently multiplies two 8 digit numbers, and only returns the low 8 digits of the result). But.. it seems to work.
And since I haven’t been posting stuff to my blog lately, this is an attempt to get back to it.
Without further ado, here is some code:
[sourcecode lang=”C”]
/*
* A simple implementation of the ideas/algorithms in
* http://homepage.cs.uiowa.edu/~jones/bcd/bcd.html
*
* Written with the idea of potentially doing a simple calculator that
* uses BCD arithmetic.
*/
#include <stdio.h>
#include <stdint.h>
#include <inttypes.h>
typedef uint32_t bcd8 ; /* 8 digits packed bcd */
int
valid(bcd8 a)
{
bcd8 t1, t2, t3, t4 ;
t1 = a + 0x06666666 ;
t2 = a ^ 0x06666666 ;
t3 = t1 ^ t2 ;
t4 = t3 & 0x111111110 ;
return t4 ? 0 : 1 ;
}
bcd8
add(bcd8 a, bcd8 b)
{
bcd8 t1, t2, t3, t4, t5, t6 ;
t1 = a + 0x06666666 ;
t2 = t1 + b ;
t3 = t1 ^ b ;
t4 = t2 ^ t3 ;
t5 = ~t4 & 0x11111110 ;
t6 = (t5 >> 2) | (t5 >> 3) ;
return t2 – t6 ;
}
bcd8
tencomp(bcd8 a)
{
bcd8 t1 ;
t1 = 0xF9999999 – a ;
return add(t1, 0x00000001) ;
}
bcd8
sub(bcd8 a, bcd8 b)
{
return add(a, tencomp(b)) ;
}
bcd8
mult(bcd8 a, bcd8 b)
{
bcd8 result = 0 ;
bcd8 tmp = a ;
bcd8 digit ;
int i, j ;
for (i=0; i<8; i++) {
digit = b & 0xF ;
b >>= 4 ;
for (j=0; j<digit; j++)
result = add(result, tmp) ;
tmp <<= 4 ;
}
return result ;
}
int
main(int argc, char *argv[])
{
bcd8 t = 0x00009134 ;
bcd8 u = 0x00005147 ;
bcd8 r ;
r = mult(t, u) ;
printf("%X * %X = %X\n", t, u, r) ;
}
[/sourcecode]
I’ll have to play around with this some more. It shouldn’t be hard to move code like this to run on the Arduino Pro Mini, and drive 3 bubble displays (yielding 11 digits plus a sign bit) of precision. And I may not use this 8 digits packed into 32 bit format: since I want 12 digits, maybe packing only 4 digits into a 32 bit word would work out better.
Anyway, it’s all kind of fun to think about the clanking clockwork that lived inside these primitive machines.
I’ll try to post more often soon.